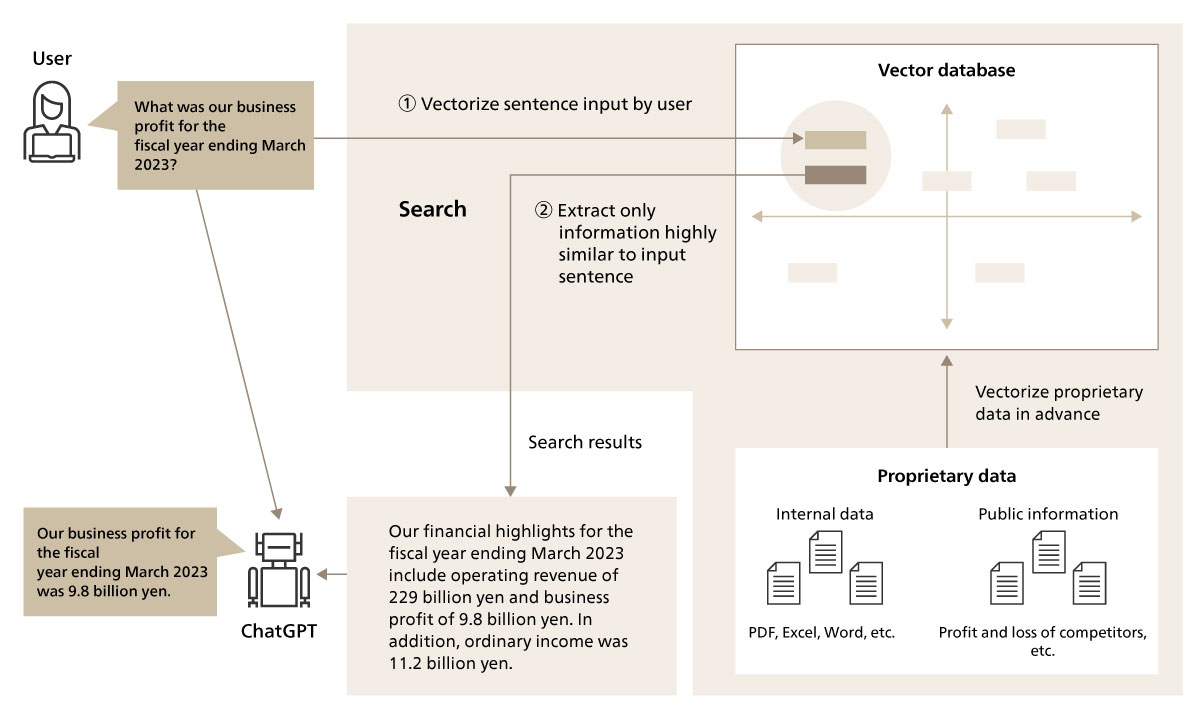
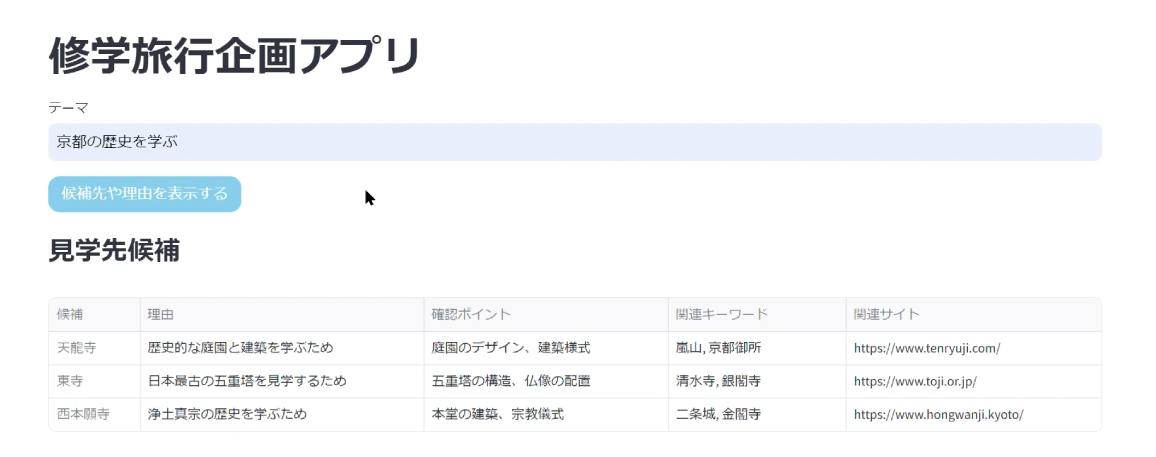
The data handled in the course of operations is not limited to text data, but also includes a wide variety of source files, such as images and PDFs, which can be searched using the RAG system.
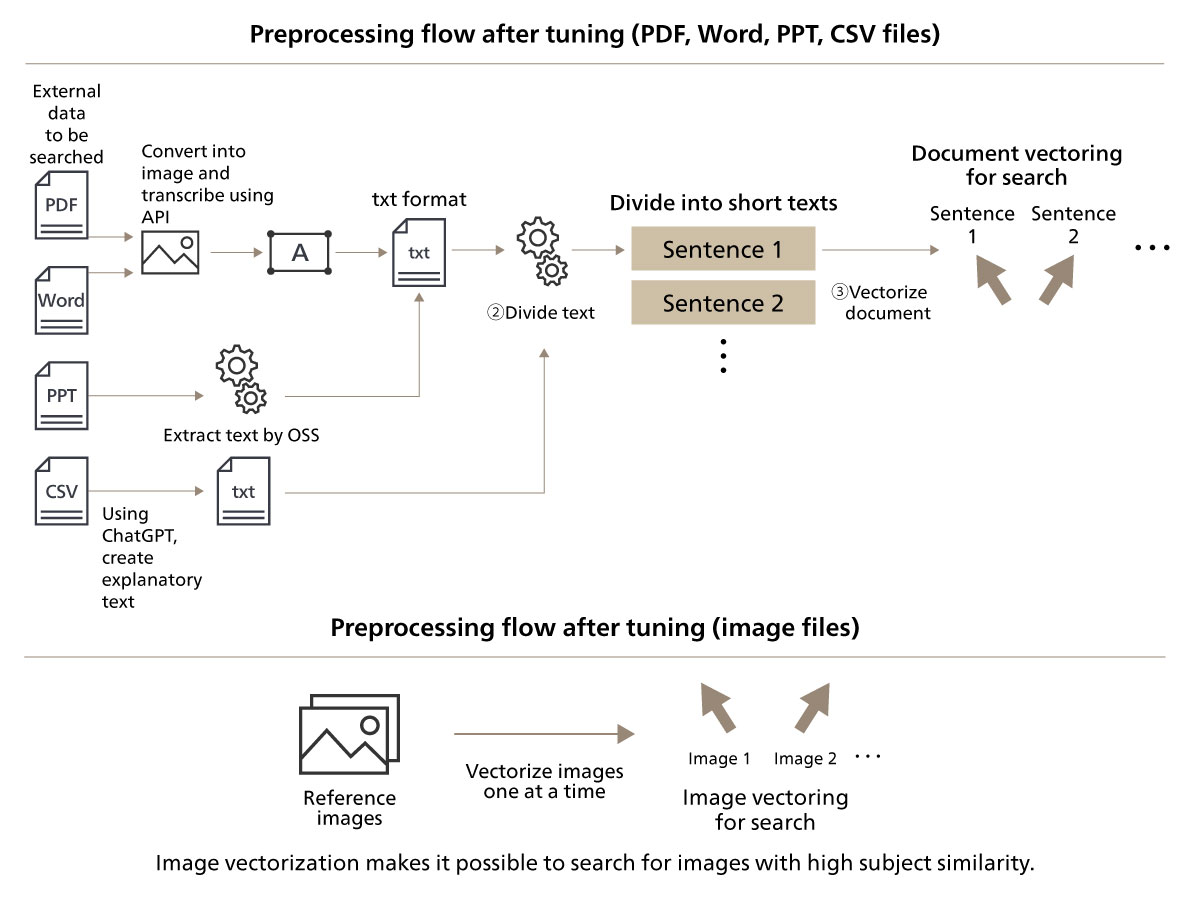
At this event as well, with practical use in mind, diverse file formats such as images, PDF, Word, PowerPoint, and CSV, were considered as search targets. Because LLMs can only read text data, we needed to preprocess these files and extract the text.
At this event, our team initially tried a method of extracting text stored in files such as PDFs using OSS libraries. This technique is effective when the text data is stored in a file such as PDF. However, the data at this event, such as PDF data, contained embedded images on web pages and did not store the text information itself, making it difficult to extract text using this method. To solve this problem, we decided to convert each file into an image and extract the text using an AI-OCR API.*4
CSV files often store data such as numbers in comma-separated format. As they are, the files tend to lack keywords and are unlikely to appear in search results. Thus, in the preprocessing stage, we used ChatGPT to create explanatory text for the tables, which was then used as the search target. This approach can have the effect of making the table data more likely to appear high in search results when needed.
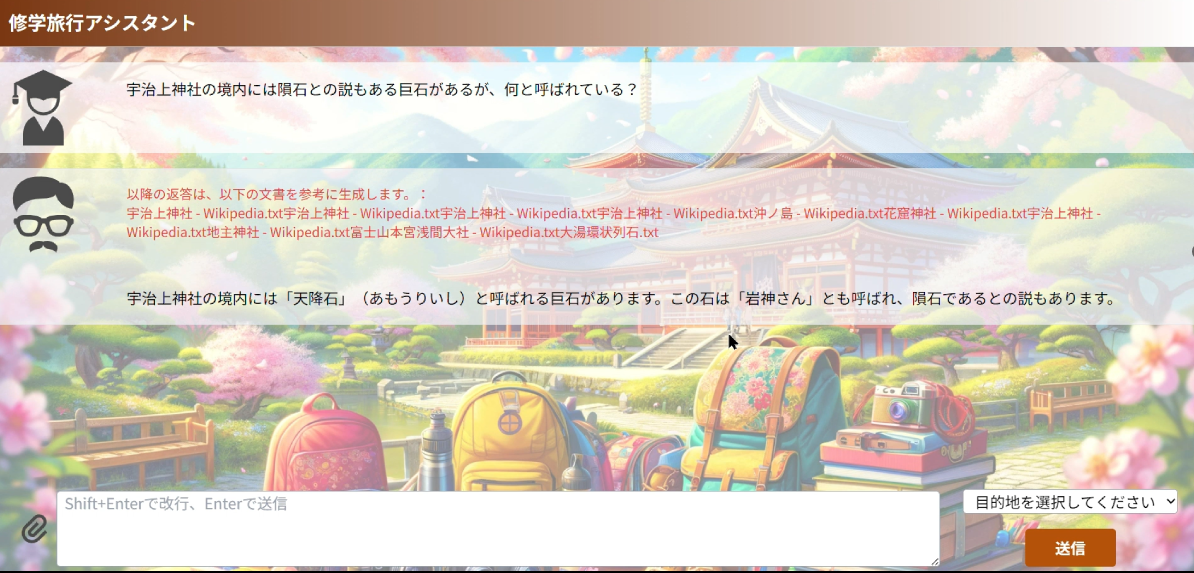
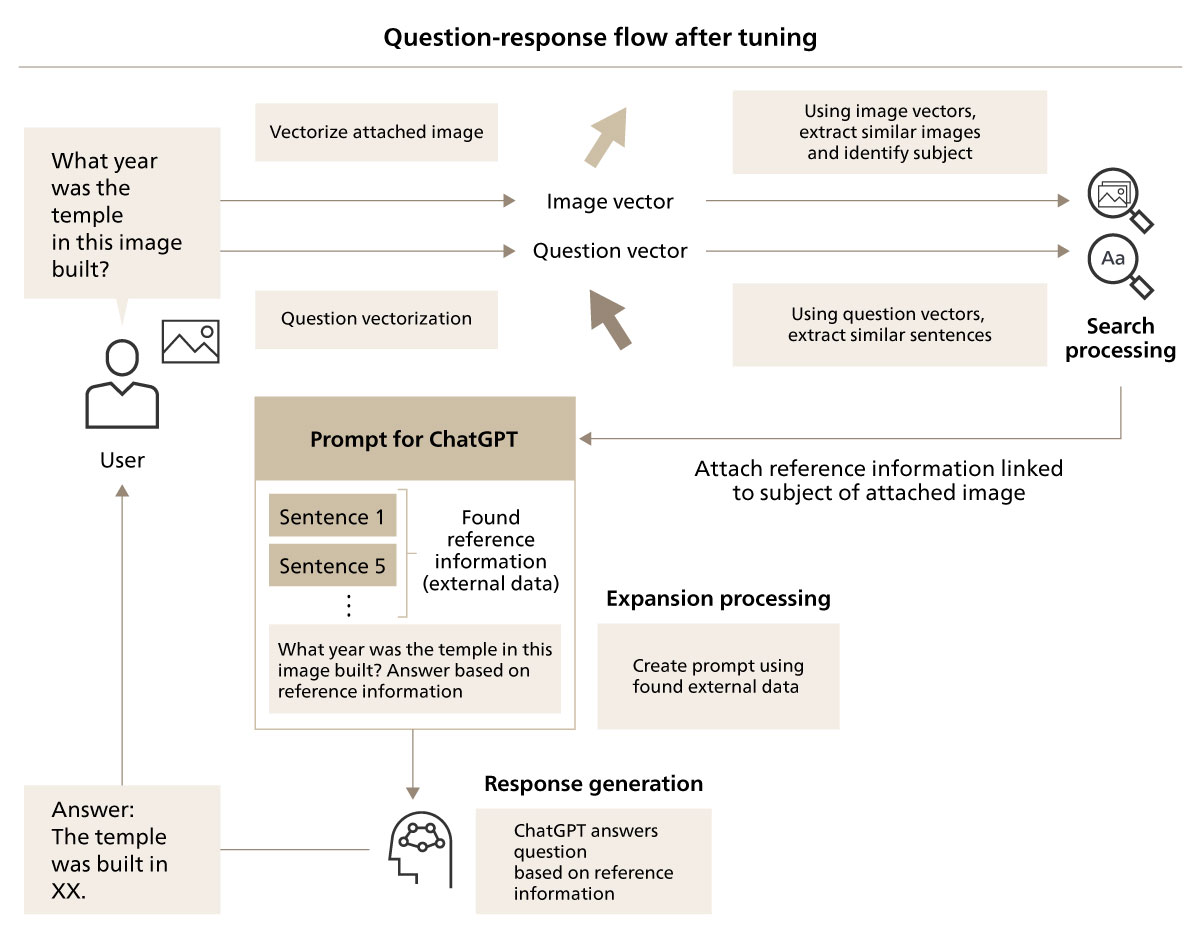
As mentioned in the “event overview” section above, the user questions assumed at this event include questions with attached photo data (for example, “Where is the temple or shrine in this photo?”). With such question, the subject of the photo needs to be identified before answering the question. We therefore adopted a technique of vectorizing the image input by the user and comparing the image with vectors of images registered in advance. This made it possible to identify the subject of the photo attached by the user and answer the question.
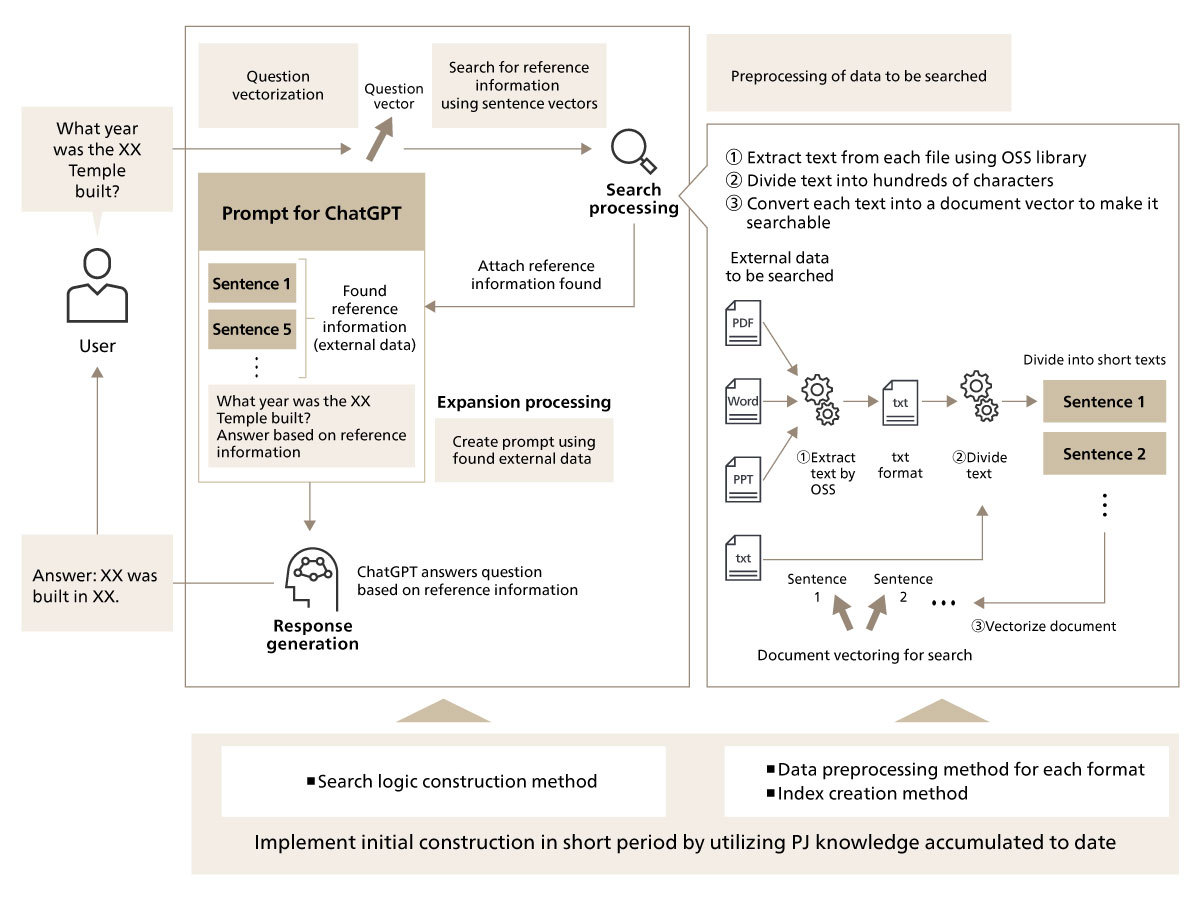
Thanks to this tuning, it was now possible to search a total of over 600 files, including text, images, PDFs, Word, PowerPoint and CSV files, having a total size of over 200 MB, in an integrated manner on the RAG system. Figure 8 shows the preprocessing flow for RAG architecture and Figure 9 shows the question-response flow, after tuning.
In implementing the RAG system in this way, it is necessary to determine the format and type of data to be searched, and facilitate a search for each using the appropriate method.