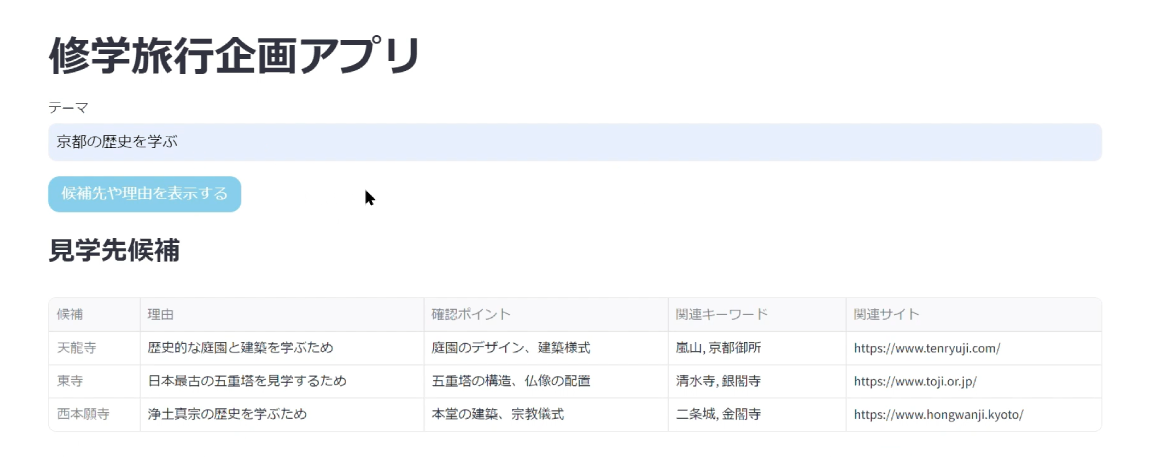
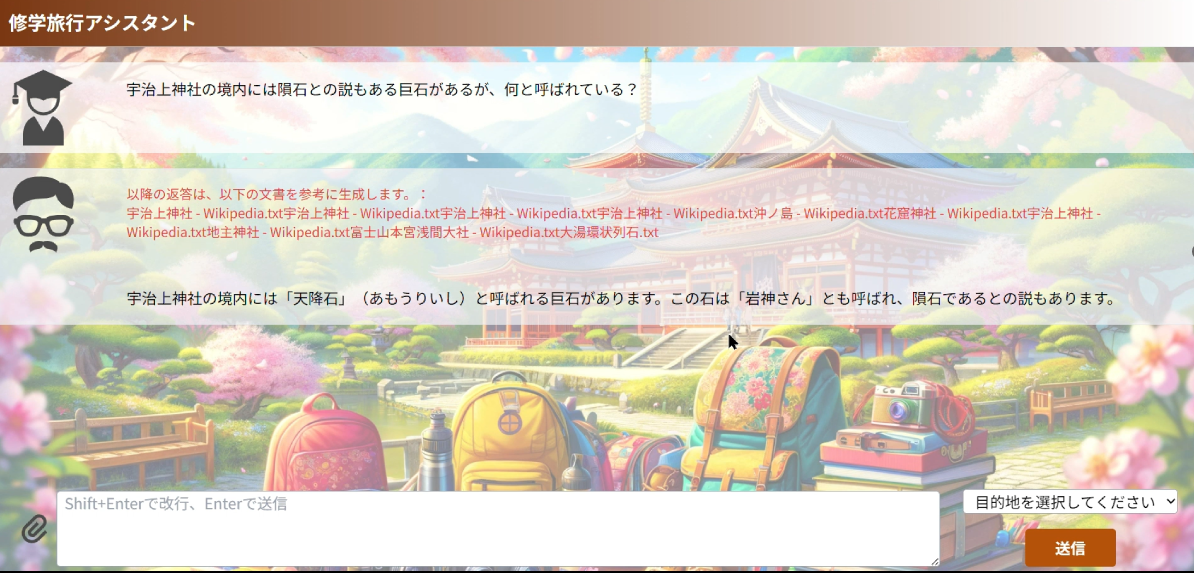
ChatGPTなどのAIサービスが企業の事業価値創出や生産性向上に有用であることに疑いはないが、企業が従業員に対して必要なAIサービスを提供できていないことで、従業員自身がAIサービスを持ち込んで利用する「Bring Your Own AI」(BYOAI, 私的AI利用)が徐々に広がりを見せている。企業がルールや利用状況を管理していない、無許可のBYOAIの場合は営業上の機微情報漏洩リスクや個人情報漏洩リスクがともない、企業統治上も問題がある。マイクロソフト社とLinkedIn社が2024年6月6日に発表した「2024 Work Trend Index」の調査によると、国内のAIユーザーの約80%が私的なAIツールを職場に持ち込んでいるとされる。企業データをセキュアに扱うことのできるAI環境の整備は急務であり、守りのDXの観点からも重要である。
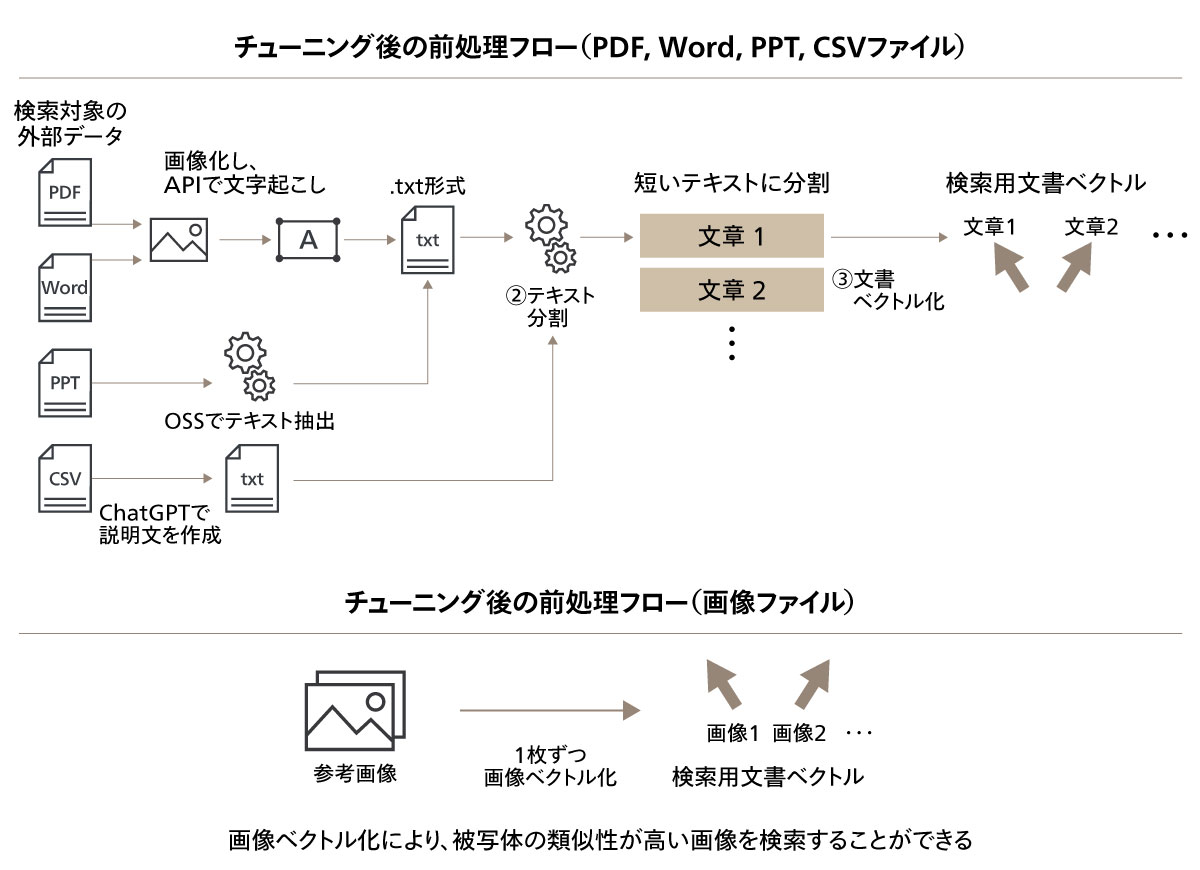
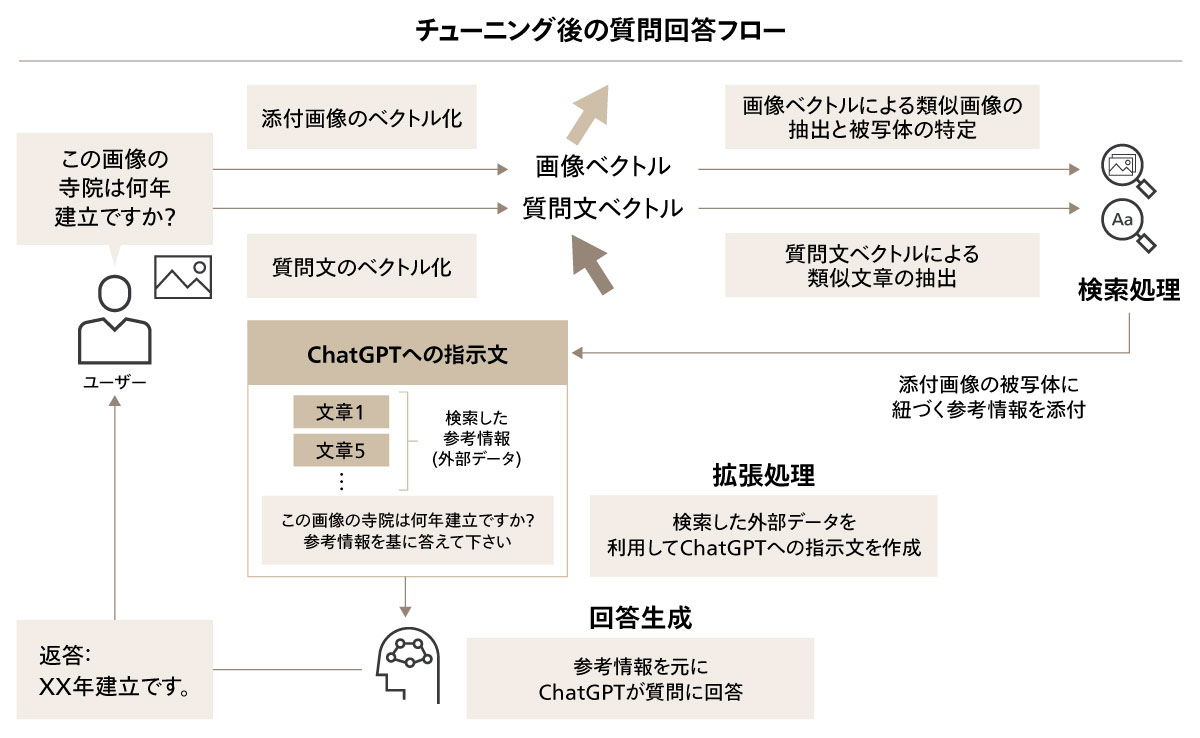
こうした背景において、RAGシステムを含めてセキュアなAI環境の構築が求められる。RAGシステムの実装においては、クラウドインフラを活用することが多い。LLMは利用に膨大な計算リソースを必要とするため、オンプレミスでの環境構築に適していないことが主な理由である。クラウドインフラを活用する際には、クラウド環境の強固なセキュリティ対策を適切に活用することが重要である。
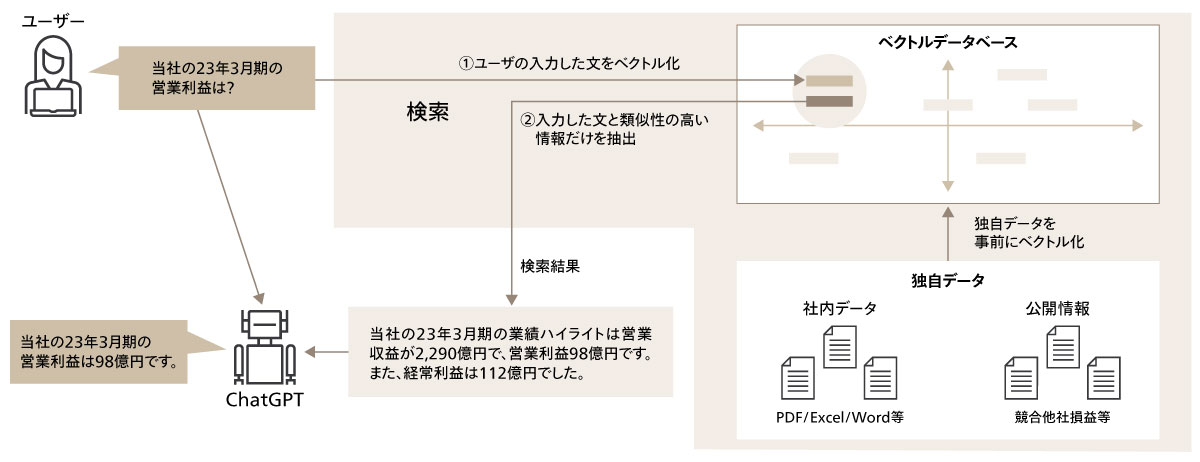
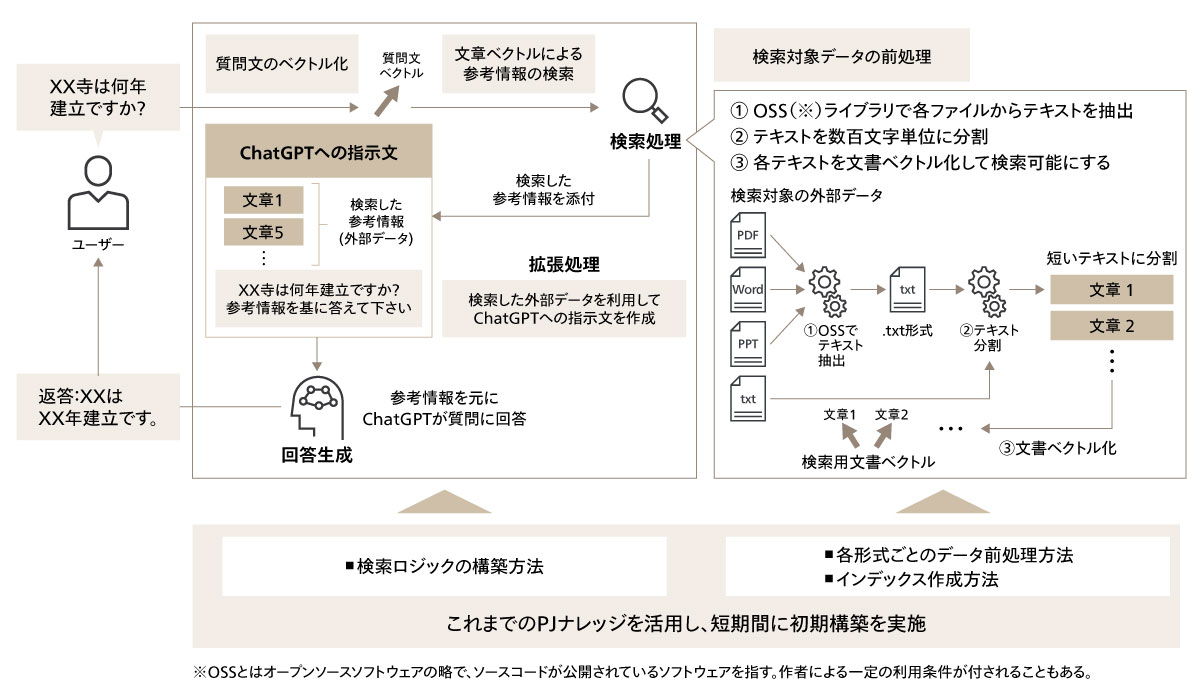
例えば、検索対象データを格納するベクトルデータベースにおいては、外部からの不正アクセスやデータ漏洩を防ぐために、限られたWebアプリ及び開発メンバーのみがアクセス可能となるように認証管理を行う必要がある。また、インターネットからの接続を遮断した閉域網を構築し、閉域網内でWebアプリからベクトルデータベースにアクセスすることが推奨される。なお、データベースに保存する全てのコンテンツに対してデータ暗号化を適用する必要がある。
次に、Webアプリに対しても同様の対策を講じる必要がある。外部からのAPIアクセスによるデータ漏洩を防ぐために、限られた開発メンバーやグループのみがアクセス可能となるように設定し、関連するストレージに対してはデフォルトの暗号化キーを使用する。
Webアプリケーションから接続するLLMなどのAPIサービスにおいても、同様のアクセス制御などを適用する必要がある。また、送信したプロンプトや出力データを監査などの目的で一定期間保存する場合には、機微な情報が利用ログに残らないように配慮する必要がある。APIアクセスの認証キーの管理は安全なストレージから取得する形とし、ソースコードに直接埋め込まない設定が一般的である。
さらに、セキュリティ対策として、不正アクセスの検出やセキュリティ基準によるリソース設定状態のチェックを行う専用のセキュリティツールを使用する必要がある。また、インシデント発生時には自動的に通知が行われるシステムを構築し、迅速な対応ができる体制を整えることが重要である。
これらのセキュリティ対策を実施することで、クラウドインフラ上でのRAGシステムの運用においてエンタープライズグレードのセキュリティを確保し、安全に企業データを扱うことが可能となる。
本イベントではこうしたセキュリティ対策を取りまとめて示し、審査員から一定の評価を得ている。